

pandas는 데이터 조작, 분석을 쉽게 할 수 있도록 해주는 파이썬 라이브러리입니다.
처음 들었을 때 왜 이름이 pandas인지 궁금했는데, "Python 데이터 분석" 이라는 단어에서 따왔다는 정보를 알게 되었습니다. 동물과는 관계가 없었네요.
이 라이브러리 또한 NumPy와 비슷하게 C언어와 파이썬으로 제작되었습니다.
import pandas as pd
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 190],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85, 35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}
data
'''
{'이름': ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교': ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키': [197, 184, 168, 187, 188, 202, 188, 190],
'국어': [90, 40, 80, 40, 15, 80, 55, 100],
'영어': [85, 35, 75, 60, 20, 100, 65, 85],
'수학': [100, 50, 70, 70, 10, 95, 45, 90],
'과학': [95, 55, 80, 75, 35, 85, 40, 95],
'사회': [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기': ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']}
'''라이브러리를 불러오는 방식은 저번 글에 소개했던 NumPy와 동일합니다.
여기서는 그저 이름이 pandas와 pd로 바뀌었다는 점밖에 없습니다.
일단 분석할 데이터를 불러왔습니다. (제가 만든 데이터가 아닙니다.)
DataFrame
df = pd.DataFrame(data)본격적으로 pandas의 테이블을 불러와 보도록 하겠습니다.

실행시키면 이런 깔끔한 테이블 하나가 출력되게 됩니다.
(브라우저에서 실행되는 Jupyter Notebook일 경우, 빈 값이 NaN으로 표시될 수 있습니다.)
특정 열만 불러오기
df[["이름"]]
df[["이름", "키", "국어"]]
여러 열을 불러오는 것 또한 가능합니다.
이번에는 "이름" 옆에 있는 숫자들(0, 1, 2, 3...)을 바꿔보도록 하겠습니다.
DataFrame(데이터, index = ["값"])
df = pd.DataFrame(data, index = ["1번", "2번", "3번", "4번", "5번", "6번", "7번", "8번"])
df
아까 봤던 테이블이랑 뭔가 좀 다르죠?
앞에 0, 1, 2, 3이 1번, 2번 3번으로 변경되었습니다.
하지만 해당 값이 원본 테이블에는 저장되지 않는다는 점, 유의해 두세요.
index.name = "인덱스 이름"
df.index.name = "지원번호"
df
앞서 설정한 인덱스 위에 "지원번호" 라는 이름이 붙은 것을 확인하실 수 있습니다.
index.name은 인덱스의 이름을 지정하는 명령어입니다.
reset_index()
df.reset_index()
# 출력 시 1번, 2번, 3번... 은 그대로 유지
df.reset_index(drop = True)
# 출력 시 0, 1, 2, 3... 출력말 그대로 인덱스의 이름을 초기화하는 명령어입니다.
하지만 해당 명령어로는 완전한 초기 상태로 되돌아갈 수 없습니다. 0, 1, 2, 3.. 으로 돌아가고 싶다면 괄호 안에 drop = True 를 입력합니다.
set_index()
df.set_index("이름")
인덱스가 숫자가 아닌, 이름로 변하였습니다.
sort_index()
df.sort_index()
# df.sort_index(ascending = False)
테이블의 인덱스를 기준으로 오름차순 정렬을 실행합니다.
반대로 내림차순은 괄호 안에 ascending = False를 넣습니다.
sort_values("열")
df.sort_values("키")
# df.sort_values(["수학", "영어"])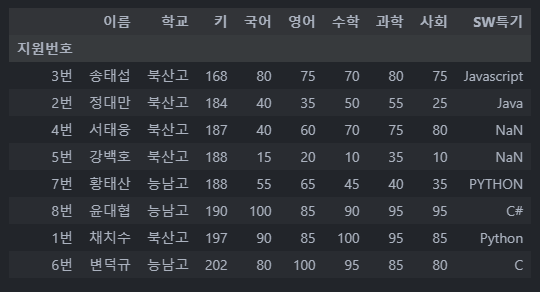
"열"을 기준으로 테이블을 정렬합니다.
ascending은 이곳에서도 작동됩니다.
두개의 열을 넣을 시에는 첫번째 열을 비교하고, 같으면 두번째 열을 비교하여 정렬합니다.
csv, xlsx, txt로 저장
df.to_csv("score.csv", encoding = "UTF-8-sig", index = False)
# csv 파일로 저장
df.to_csv("score.txt", sep = "\t")
# txt 파일로 저장
df.to_excel("score.xlsx")
# xlsx 파일로 저장딱히 더 설명할 것은 없는 함수입니다..
저장한 파일 불러오기
pd.read_csv("score.csv")
# 파일 그대로 불러오기
pd.read_csv("score.csv", skiprows = 1)
# 위에서부터 열 하나 건너뛰고 불러오기
df
원래라면 맨 위에 "채치수"가 있어야 하는데 사라진 모습을 볼 수 있습니다.
describe()
df["키"].describe()
'''
count 8.000000
mean 188.000000
std 9.985704
min 168.000000
25% 186.250000
50% 188.000000
75% 191.750000
max 202.000000
Name: 키, dtype: float64
'''자료의 구체적인 정보를 불러옵니다. "설명하다"인 description의 약자로 추정됩니다.
min()
df["키"].min()
'''
168
'''자료의 최솟값을 불러옵니다.
max()
df["키"].max()
'''
202
'''자료의 최댓값을 불러옵니다.
nlargest(숫자)
df["키"].nlargest(3)
'''
지원번호
6번 202
1번 197
8번 190
Name: 키, dtype: int64
'''N번째까지 큰 값을 불러옵니다. nsmallest와 반대로 작동합니다.
nsmallest(숫자)
df["키"].nsmallest(3)
'''
지원번호
3번 168
2번 184
4번 187
Name: 키, dtype: int64
'''N번째까지 작은 값을 불러옵니다. nlargest와 반대로 작동합니다.
mean()
df["키"].mean()
'''
188.0
'''해당 열의 평균을 구합니다.
count()
df["SW특기"].count()
'''
6
'''해당 열의 데이터 개수를 구합니다. NaN은 포함하지 않습니다.
unique()
df["학교"].unique()
'''
array(['북산고', '능남고'], dtype=object)
'''해당 열에서 '특별한 값'을 불러옵니다. 말 그대로 unique 한 값들입니다.
nunique()
df["학교"].nunique()
'''
2
'''unique() 의 개수를 출력합니다.
loc[]
df.loc["5번"]
'''
이름 강백호
학교 북산고
키 188
국어 15
영어 20
수학 10
과학 35
사회 10
SW특기 NaN
Name: 5번, dtype: object
'''
df.loc["1번", "국어"]
'''
90
'''
df.loc[["1번", "2번"], "영어"]
'''
지원번호
1번 85
2번 35
Name: 영어, dtype: int64
'''
df.loc["9번"] = ["이정환", "해남고등학교", 184, 90, 90, 90, 90, 90, "Kotlin", 450, "Pass"]
'''
데이터를 추가합니다.
'''
df.loc["4번", "SW특기"] = "Python"
'''
4번 인덱스의 SW특기를 Python으로 변경합니다.
'''
dfloc는 굉장히 다양한 형태로 쓰일 수 있습니다.
한 열의 데이터만 가져올 수도 있고, 행과 열을 같이 가져올 수도 있습니다.
필터
filt = (df["키"] >= 185)
df[filt]
# df[df["키"] >= 185] 위와 똑같은 소스
# df[~filt] 반대값 출력
키가 185 이상인 데이터만 출력하는 코드입니다.
대괄호 안에 ~filt 라고 쓰게되면 반대 값이 출력됩니다.
변수 명이 꼭 filt 이여야 할 필요는 없습니다.
str.startswith("문자")
filt = df["이름"].str.startswith("송")
df[filt]
특정 열에서 "문자"로 끝나는 데이터만 불러옵니다.
str.contains("문자")
filt = df["이름"].str.contains("태", na = True)
df[filt]
# na = False 일 시, NaN 값은 제외
특정 열에서 "문자"가 포함된 데이터만 불러옵니다.
isin(값)
langs = ["Python", "Java"]
filt = df["SW특기"].isin(langs)
df[filt]
'''
이 소스는 SW특기의 값들을 모두 소문자로 만듭니다.
대문자는 lower() 대신 upper() 함수를 이용합니다.
langs = ["python", "java"]
filt = df["SW특기"].str.lower().isin(langs)
df[filt]
'''
특정 열에서 특정 값들이 포함되어 있는 데이터만 불러옵니다. 대소문자를 구분합니다.
nan
df["학교"] = np.nan
df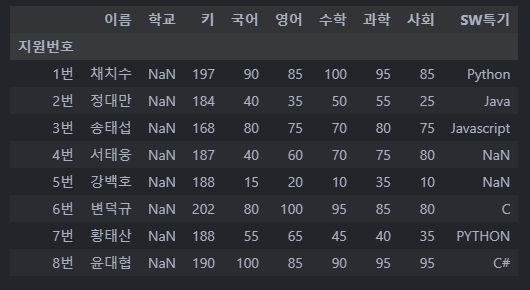
특정 열의 모든 데이터를 NaN으로 바꿔버립니다.
fillna("문자")
df.fillna("몰라")
NaN인 값들을 모두 "문자"로 변경합니다.
dropna()
df.dropna()
df

NaN이 하나라도 포함되어 있으면 해당 인덱스를 제거합니다.
replace()
df["학교"].replace({ "북산고":"선린고", "능남고":"디미고" })
'''
지원번호
1번 선린고
2번 선린고
3번 선린고
4번 선린고
5번 선린고
6번 디미고
7번 디미고
8번 디미고
Name: 학교, dtype: object
'''데이터의 이름을 변경합니다.
groupby()
그룹별로 나누고, 그 안에서 데이터를 구하는 방식입니다.
df.groupby("학교").get_group("북산고")
"학교" 라는 그룹에서, "북산고" 인 값만 불러옵니다.
df.groupby("학교").mean()
df.groupby("학교")["키"].mean()
'''
키 평균 출력
학교
능남고 193.333333
북산고 184.800000
Name: 키, dtype: float64
'''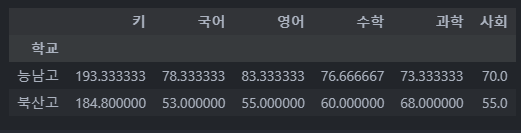
"학교" 라는 그룹의 데이터 평균을 출력합니다. (평균은 정수형 자료만 가능하므로 정수형 자료만 출력)
df.groupby("학교").size()
'''
학교
능남고 3
북산고 5
dtype: int64
'''"학교" 라는 그룹의 데이터 개수를 출력합니다.
df.groupby("학교").size()["능남고"]
'''
3
'''"학교" 라는 그룹 안에서 "능남고" 라는 데이터의 개수를 출력합니다.
'🖥️ 프로그래밍' 카테고리의 다른 글
| [미완성] 데이터 분석 - 타이타닉 생존자 예측 (0) | 2022.06.07 |
|---|---|
| 행렬, 테이블을 넘어 그래프로 - Matplotlib (0) | 2022.05.29 |
| 행렬관련 계산을 빠르게, NumPy (0) | 2022.05.17 |
| 코드 분석 - 포인터와 배열 (0) | 2022.04.17 |
| 보다 더 많은 양의 데이터를 편하게! - 배열과 문자열 (0) | 2022.04.12 |